分类 其他 下的文章
通用数据平台搭建
数据流格式设计
数据流信息包含时间戳、用户唯一id、用户画像信息、用户行为信息,而好的数据流需要满足通用、可扩展、占用空间少等特性,可设计如下:

timestamp:数据流产生的时间戳,占4字节。
uid:为用户全服唯一id,占4字节,对于可能超过4亿的用户,建议用8字节。
flag:用户画像标识位,用来标示数据流中都含有哪些用户画像信息,占1字节,可最多表示8种用户画像信息,目前常用的画像信息包含性别、年龄、地域、设备、渠道等,所以1个字节基本够用。很多人会疑问,每种数据流或仅登录数据流中包含所有用户画像信息不就ok了吗,但为了全面分析不同数据流的用户画像分类结果又要剔除一些不需要所有用户画像的数据流,这是全面性和存储空间的平衡设计。譬如在登录数据流中需要尽可能包含所有用户画像信息,在付费数据流中,你可能更关注的是性别和年龄而非所有用户画像信息,这个时候就需要flag来标识。
profile:用户画像信息,性别、年龄、地域、设备取值范围可用1字节表示,渠道号各种类型都有,可用字符串表示。
action:用户行为,包括注册、登录、付费、提现、看广告、自定义界面点击等,简单应用可用1字节表示,大型应用可用2字节表示。
para:用户行为参数,对于登录,参数可为空,付费,则为充值金额,购买,则为商品信息,包括商品数量、种类等。
数据流存储与处理
传统的数据库很难对海量的数据进行存储与处理,而hadhoop的特性刚好与用户行为数据的特点不谋而合,一般都是大规模、写一次读多次,且hadoop会尽量将数据处理任务分配到离数据存储最近的节点上,可减少数据传输时间,但hadoop的使用属于程序的工作,不再赘述。
为了便于讲解数据流的通用处理,数据流用Flow表示,每个action对应的数据流用Fa表示。对于一个action产生的指标集为不同维度下的次数、人数、人均次数,这里次数是指广义上的次数,不仅包括狭义上的次数,还包含可累加参数值求和,对于人均次数稍后可用表达式来实现,暂不讲。若维度数量用Dn表示,Flow中用户画像字段数用Un表示,分类参数数量用Pn表示,则Dn=Un+Pn。讲到这里,绝大部分人都会懵,因为太抽象了,我给大家举个例子。
拿购买Flow来讲,通常购买Flow中会包含用户的性别和年龄信息,其action对应的para会包含购买数量、商品颜色等信息,这里的性别和年龄表面上是用户画像字段,其本质上也是分类参数,因为我们不关心用户画像的累加,而仅关心其分类,同样商品的颜色也是分类参数,但商品的数量通常我们不关心其分类,仅关心累计购买多少数量,所以其指标集包含两种情况,一种是狭义上的次数,不同性别、不同年龄段、不同商品颜色的点击购买次数、人数,另一种为广义上的次数,不同性别、不同年龄段、不同商品颜色的购买总数量、人数,两种情况下的人数含义相同,取其一即可。
因此,要想从原始Flow得到其指标集,首先确定Flow中的para哪些是分类参数,哪些是累加参数,然后把画像中的字段和分类参数一起组成维度组,最后在求得各累加参数和不含累加参数两种情况下,对维度组的所有排列结果,且每个维度组的排列都对应一个维度组的分类树。讲到这里,几乎所有人都会懵,因为比刚才还TM抽象,我再举个例子。
还拿购买Flow来讲,维度组D={sex、age、color},累加参数组Pa={num},维度组的所有排列为A(3,3)=6,即有6种可能的排列,例如D1={age、sex、color},表示年龄段为一级分类,性别为二级分类,颜色为三级分类,D2={color、sex、age},表示颜色为一级分类,性别为二级分类,年龄为三级分类,因此维度组的所有排列就是为了罗列每个维度所在分类级别的所有情况。至于分类树比较好理解,当确定了维度组D={sex、age、color}之后,性别只有男女两种情况,当然不排除第三种情况,年龄可分为(0, 20)、[20,40)、[40,-1),颜色可分为红、黄、蓝,分类树如下图:
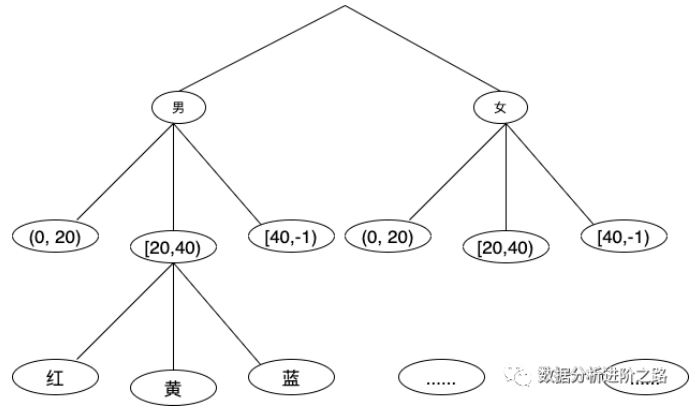
其中,分类树中的每一个节点都代表每级确定分类下的广义次数和人数。例如女性节点代表女性用户的购买总金额和人数,女性节点下的第一个子节点代表女性用户中20岁以下用户的购买总金额和人数。
由此可见,指标集个数=(累加参数数量+1)*维度组的排列数,每个指标又存在一个分类树,计算量会很大,但通常数据分析的需求不会有这么多种情况,所以可以动态的传递需求参数来获取我们想要的结果。
需求参数有4个,第一个参数用来标记para中哪些是累加参数,哪些是分类参数,第二个参数用来确定要计算的是累加参数还是非累加参数,若是累加参数,具体又是哪个累加参数,第三个参数用来确定维度组是如何排列的,第四个参数用来确定分类树中的哪个节点。
以上讲的是针对一个action的指标计算,那多个action的情况呢,例如在计算DAU时,仅需要Login这一个action的Flow,但若计算注册留存,就需要Register和Login两个action的Flow来处理,这类情况就很难通用处理,好在数据分析时这种情况不多,我们可以对多个action共同决定的指标做单独处理,但维度组和分类树的思想是不变的,只是维度组不再是确定的,根据实际需求自定义即可。
写到这里,很多人觉得数据处理应该到此结束,但很不幸的是,处理到这种程度是远远不够的,因为之前处理的都很纯粹,就是计算次数和人数,若想知道人均次数、各环节转化率、arpu等,之前计算就很难满足。为了解决这类问题,我们引入合成指标的概念,若合成指标用Ic表示,各action的指标用Ia表示,则Ic=F(Ia1, Ia2...),F为运算,包括算术与函数运算。这里算数运算可以仅实现加减乘除带括号就足够用了,函数运算可以把常用的求平均、求最值等实现即可,这里需要用到编译器相关知识,没关系交给程序就好了。除此之外,还需要对值进行修饰,譬如保留精度、转成百分比、对合成指标命名等。最后,往往我们想同时查看多个指标的对比情况,比如把DAU和arpu放一起查看,就需要把多个指标并行计算再结果合并。以上运算、修饰、合并等可设计一个通用指标表达式即可,思想比较简单,实现却很复杂。
至此,数据处理结束,除了很少见的多个action共同参与的指标计算外,其它指标的计算在数据处理层都是通用的,没有特殊逻辑,每个指标的定义都是通过action的Flow定义、四个输入参数、指标表达式来决定,分类树节点参数可选,这样就可以构建一个参数串到常用指标的关联,便于快速查询。
结果展示
若提供分类树,结果为一个二维表结构,横向为指标,纵向为时间,若不提供分类树,结果为一个N维表结构,若分类树深度为D,则N=D+2,N维表结构需要二维化到平面才能显示,可采用表格嵌套来实现,如下图所示:
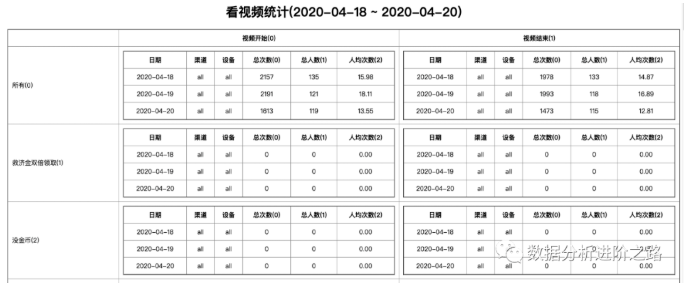
多维表格用html实现比较简单,若导出至excel,就需要由内而外计算每层表格所占单元格的长宽,然后进行单元格合并,这个过程也是相当复杂,目前还没见过哪个数据平台能导出多维表格,感兴趣的读者可留言。
虽说多维表格是一个很通用的数据展示方式,但不够形象直观,对于比较常用或重要的数据可接入AntV来显示各种统计图。
还有一些需要实时显示的指标,例如用户增长、付费增长、同时在线人数等,可每隔一段时间自动请求处理并显示。
至此,结果展示结束,很多大公司的数据平台基本都是如此。但从通用性的角度来讲,以上提到的很多抽象的概念和思想,目前商用的数据平台基本都不具备。
通用数据平台的搭建,到此讲解完毕,本篇可能太注重思想,缺乏一些实际的项目来实践,导致看完后会觉得晦涩难懂,但仔细思考后就会有豁然开朗的感觉,思想高度会有很大的提升!项目地址:https://github.com/song2010040402102/log_track