songxu 发布的文章
GMP源码剖析
1. GMP简介
G: goroutine,用户级线程或协程,在用户态调度
M:machine,内核级线程,在内核态调度
P:processor,存放G队列,P必须绑定M,队列中的G才可以执行
m0:主线程对应的结构
g0:每个M都绑定一个g0,栈的大小为8K,用来执行runtime的代码
2. 入口函数
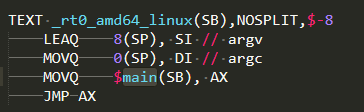
_rt0_【ARCH】_【OS】,例如ARCH为amd64,OS为linux的入口函数为_rt0_amd64_linux,如下图:
3. TLS
TLS(Thread Local Storage),每个线程会绑定m.tls的地址,tls类型为[6]uintptr,首个元素为当前运行的g,g中保存m
4. 运行前的准备工作
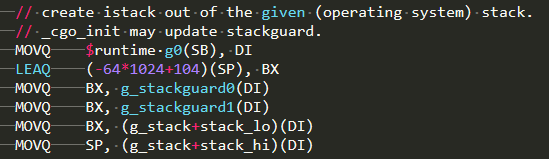
a. 初始化m0所绑定的g0的栈,大小约64k,区别于其他m所绑定的栈为8K的g0,如下图:
b. 绑定m0与g0,如下图:

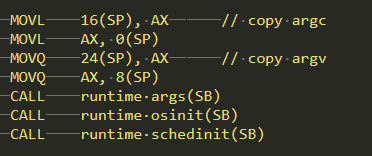
c. 命令行参数、系统信息、调度等初始化,如下图:
5. 主goroutine的创建
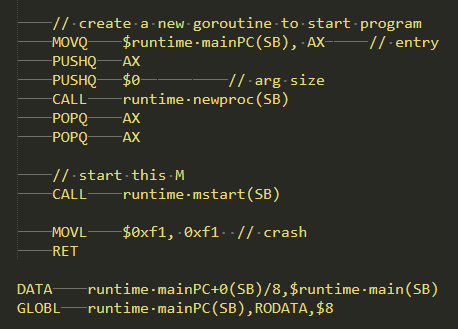
main函数所在的goroutine的创建,如下图:
其它goroutine由go关键字来创建,编译器会自动把go关键字转成newproc函数
6. goroutine调度
每个的线程的入口函数都是mstart,mstart执行schedule,schedule依次从本地P、全局P、其它P、netpoll中取g
如果都没有取到,线程则休眠,一旦取到,则调用execute来执行,若当前goroutine执行完毕,则调用goexit0继续调度
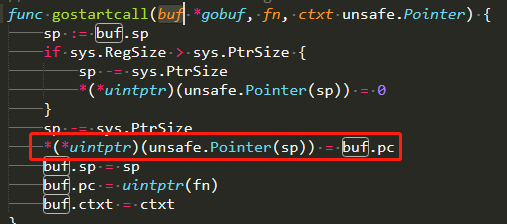
自动执行goexit0的原因在于创建goroutine的时候,把goexit的函数地址设定到goroutine根函数返回时pop所在的栈位置
ret指令会执行pop pc,如下图:

7. 系统监控
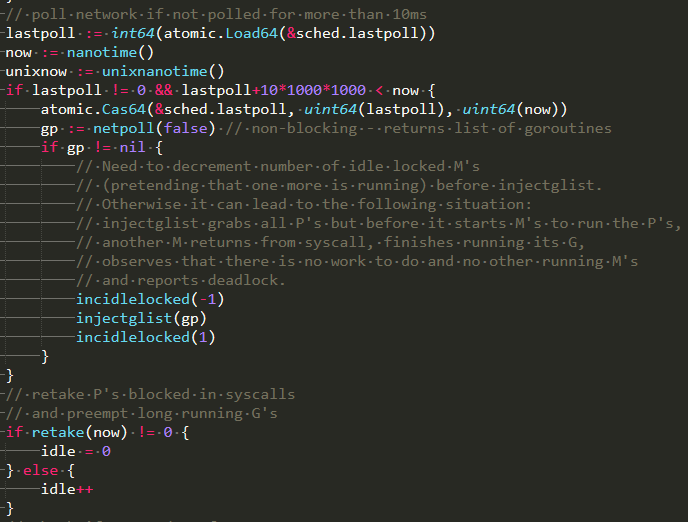
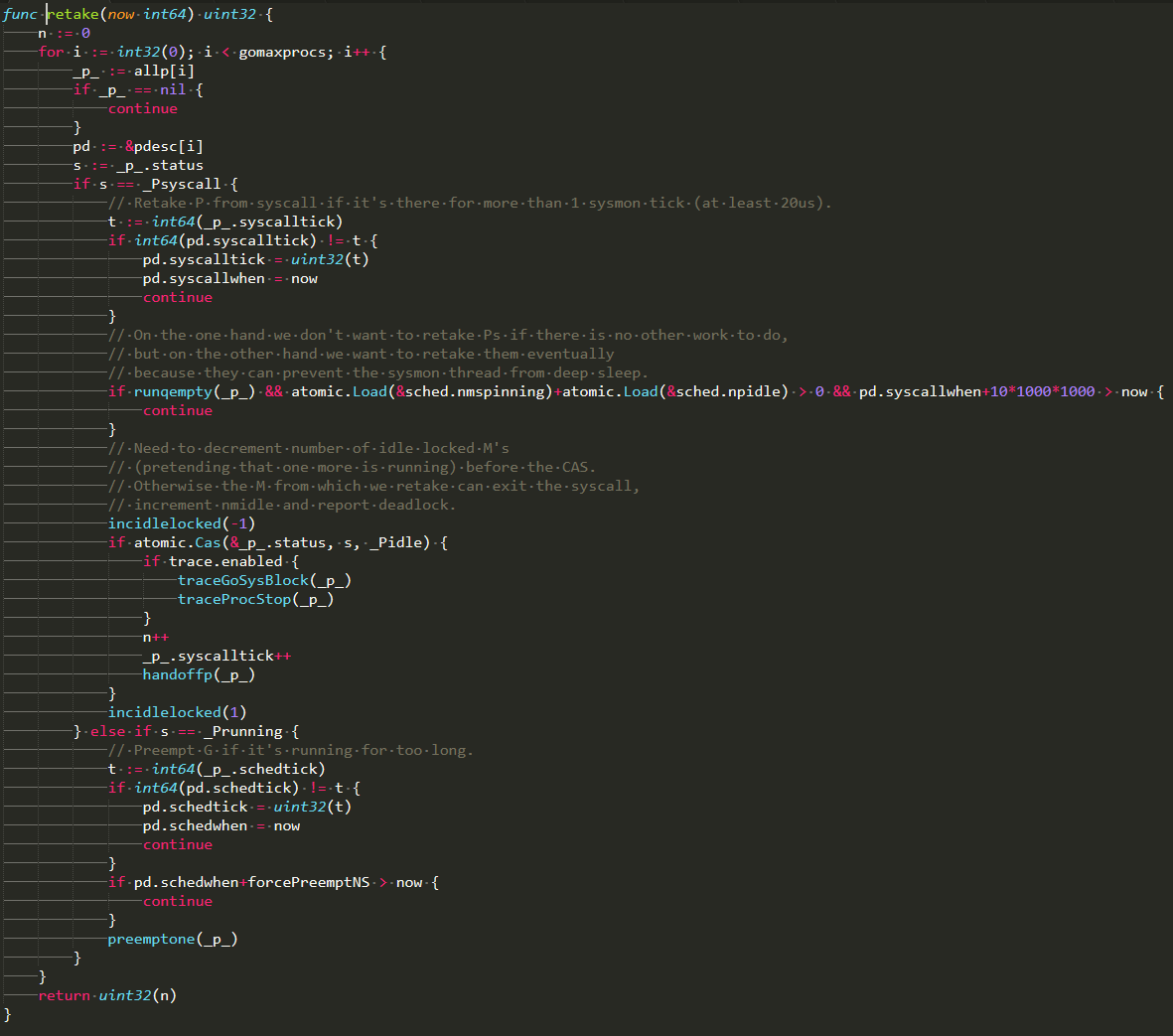
goroutine会专门启动一个线程来处理netpoll、长时间运行的goroutine,如下图:
a. 如果已经有可读或可写的goroutine并且超过10ms得不到执行,则加入全局P中
b. 如果某个goroutine长时间处于运行状态超过10ms,则会被标记成抢占状态,待调用某个函数时因栈溢出触发morestack函数,进而被其他goroutine抢占
c. 如果某个goroutine处于系统调用状态,如果此时本地P还有别的goroutine,或者执行时间超过10ms,则唤醒一个M与这个P绑定,进而P中剩下的goroutine可以得到执行
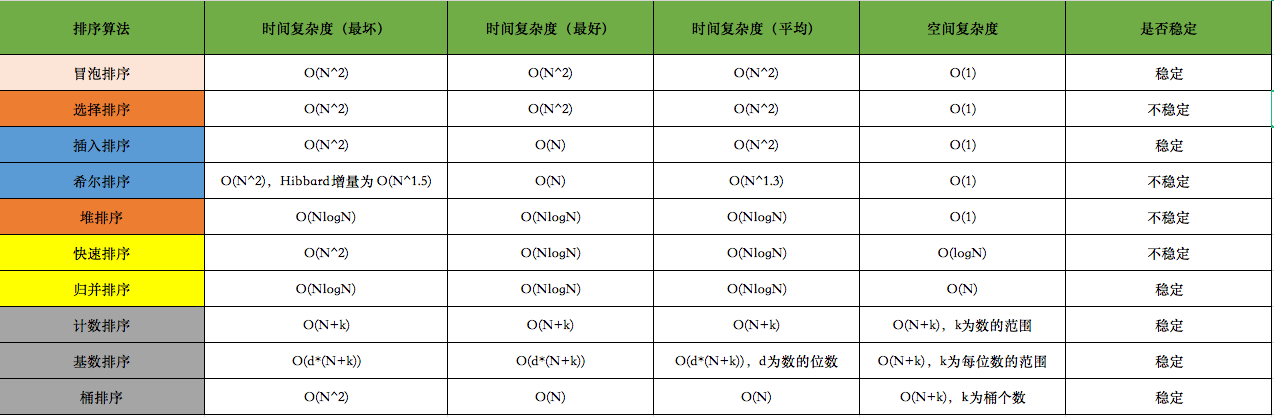
十大排序算法总结
有趣的浮点数
浮点数编码
从高到低分别是:符号位、指数位、有效数位
float:4字节,符号1位、指数8位、有效数23位
double:8字节,符号1位、指数11位、有效数52位
二进制表示
以4字节的float为例,整数部分采用除2取余法,小数部分采用乘2取整法,然后严格按照以下步骤编码:
- 正数或0符号位0,负数符号位1
- 移动小数点到第一个有效数字的右边,假定移动N位,左移N为正,右移N为负
- 若N为正,则指数位的最高位为1,剩余7位则用N-1的二进制来填充
- 若N为负或0,则指数位的最高位为0,剩余7位则用N的二进制取反来填充
- N的取之范围[-127, 127],当N为128时,则为无穷数
- 小数点右边的其余数字,依次填充有效数位即可,多余数字截断
- 为了表示更小的小数,当右移位数大于等于127位时,只移127位,此时需要借用有效数位的最高位来区分小数点前是0还是1,因此此时的有效数位少一位
取值范围
从以上分析可得出float的取值范围:最大数为1.999...pow(2, 127),最小数为pow(2, -127-22)
double的取值范围:最大数为1.999...pow(2, 1023),最小数为pow(2, -1023-51)精度
以整数为例,对于float来说,能精确表示的最大整数为pow(2, 24)
对于不在精度范围内的数,编译器和cpu采用“五舍六入”法游戏采用浮点数的误区
游戏内经常会判断两个float是否相等,采用差值的绝对值小于一个很小的数delta,这种是不严谨的,由于float的最小粒度为pow(2, -23),精确到小数点后7位,是在整数部分只占最多1bit的情况下,假设整数部分为10000,此时若delta为0.0001,会超出精度,应改成delta为0.001,可采用以下函数来判断:
bool is_float_eq(float x, float y) { return x == y || abs(*(unsigned int*)&x-*(unsigned int*)&y) == 1; }
redis集群
redis集群原理
由于redis是内存型数据库,因此想承载大量的缓存需要加集群,redis集群实现原理是一致性哈希,即把key先做hash运算,得到一个32位的整数,然后对redis的slot总数取模,再把key放到slot对应的redis节点上。若当前连接的redis节点上不存在要查询的key,此时会自动重定向key所在的redis节点,因此redis集群不支持涉及多个key的命令,例如集合取交集。
redis集群搭建
由于redis集群采用投票容错机制,即有一半以上投票某个master节点挂了,才认为此节点不可用,需要用相应的slave节点替换,因此 redis集群至少需要3个master和3个slave节点,为了方便演示采用一个虚拟机同时启动6个实例的方式。
1. 启动6个实例
mkdir redis-cluster cd redis-cluster mkdir redis1 cp redis-server redis1 cp redis.conf redis1 依次6份复制redis1 把redis.conf配置项cluster-enabled设置为yes,port改为7701、7702...7706 最后依次启动redis-server2. 创建集群
redis-cli --cluster create 127.0.0.1:7701 127.0.0.1:7702 127.0.0.1:7703 127.0.0.1:7704 127.0.0.1:7705 127.0.0.1:7706 --cluster-replicas 1添加节点
1. 添加主节点到集群
redis-cli --cluster add-node 127.0.0.1:7707 127.0.0.1:7701
2. 分配哈希槽
redis-cli --cluster reshard 127.0.0.1:7701
可选择分配多少哈希槽,以及分配方式3. 添加从节点到集群
redis-cli --cluster add-node 127.0.0.1:7708 127.0.0.1:7701
4. 构建主从关系
登录到7708:redis-cli -c -p 7708
执行集群复制命令:cluster replicate fccadebeb5b769bd084369e5cbe391979fb53b40
fccadebeb5b769bd084369e5cbe391979fb53b40为7707的节点id删除节点
1. 重分配哈希槽
redis-cli --cluster reshard 127.0.0.1:7701
源节点选择7707,哈希槽个数选择全部,接受节点随机选一个即可2. 删除主节点、从节点
redis-cli --cluster del-node 127.0.0.1:7701 masterID
redis-cli --cluster del-node 127.0.0.1:7701 slaveID
masterID为主节点id,slaveID为从节点的id