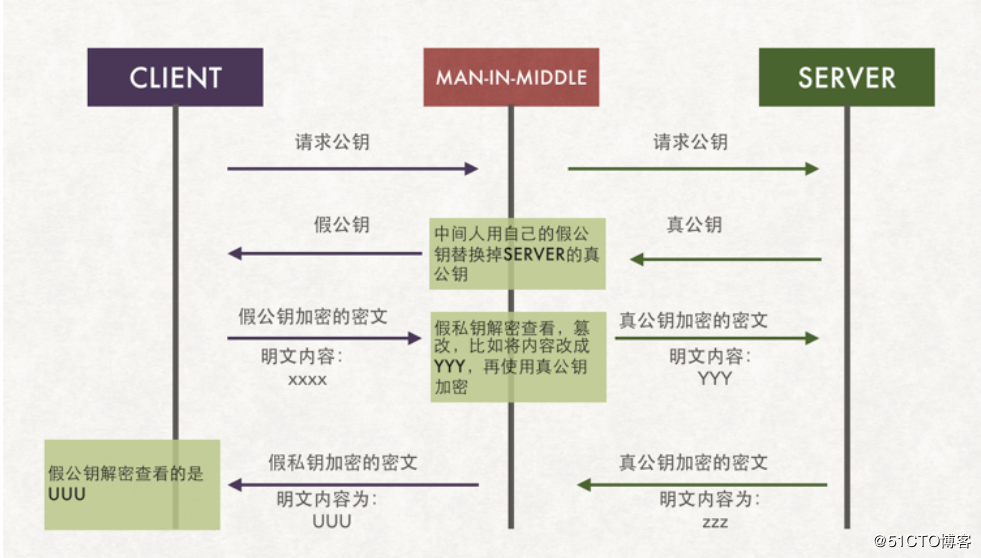
麻将AI主要包含:胡牌算法、听牌算法、N向听牌算法、出牌算法、叫牌算法
胡牌即满足3n+2,3为刻或顺,2为将,所以判断一副牌是否胡牌仅需抽出一对将,看剩下的牌是否全是刻或顺即可
在遍历一副牌时有两种方式,一种是按优先级线性遍历,即先取出一对将牌,接下来按刻>顺>对>连>单的优先级取牌;另一种采用平级树状遍历,即亦取出一对将牌后,接下来把每层的可能性递归展开
以{1万1万2万2万2万2万3万4万}为例,采用优先级线性遍历结果为{[1万1万]、[2万2万2万]、[2万3万4万]},采用平级树状遍历结果分别为{[1万1万]、[2万2万2万]、[2万3万4万]}、{[1万1万]、[2万3万4万]、[2万2万2万]},看似两种方式都可以判断是否胡牌且第二种方式反而麻烦,事实上这仅是众多牌型中非常简单且不含癞子牌情况,然而很多地方麻将规则都有癞子牌,数量通常在3、4、7张不等,甚至有些规则癞子牌不止一种,在这种情况下采用优先级线性遍历就无法判断是否胡牌,仅能采用平级树状遍历。以{1万1万2万2万3万4万5万2筒2筒3筒4筒5筒癞癞}为例,采用优先级线性遍历结果为{[1万1万]、[2万3万4万]、[2万癞癞]}...,且判断其未胡牌,而采用平级树状遍历结果为{[1万1万]、[2万3万4万]、[2万癞癞]}、{[1万1万]、[2万2万癞]、[3万4万5万]、[2筒2筒癞]、[3筒4筒5筒]}...,且判断为胡牌,所以两种方式各有优缺点
优先级线性遍历:优点算法简单、执行效率高,缺点不适用一般性地方麻将,且获取不了所有的分组情况
平级树状遍历:优点可适用一般性地方麻将,可获取所有分组情况,缺点算法复杂、执行效率稍慢。因为听牌等算法都依赖于平级树状遍历,所以接下来详细介绍其算法
平级树状遍历第一层节点为一副牌中所有可能的将牌,分三种情况:牌数大于等于2、牌数等于1、牌数等于0,例如有3个1万,可取出2个1万作将,有1个2万,可取出一个2万并凑1个癞子作将,牌数等于0只能凑两个癞子作将,第二层到最后一层则依次取出所有可能的刻和顺,分五种情况:不需要癞子的刻、不需要癞子的顺子、需要一张癞子的对、需要一张癞子的连、需要两张癞子的单,如下图所示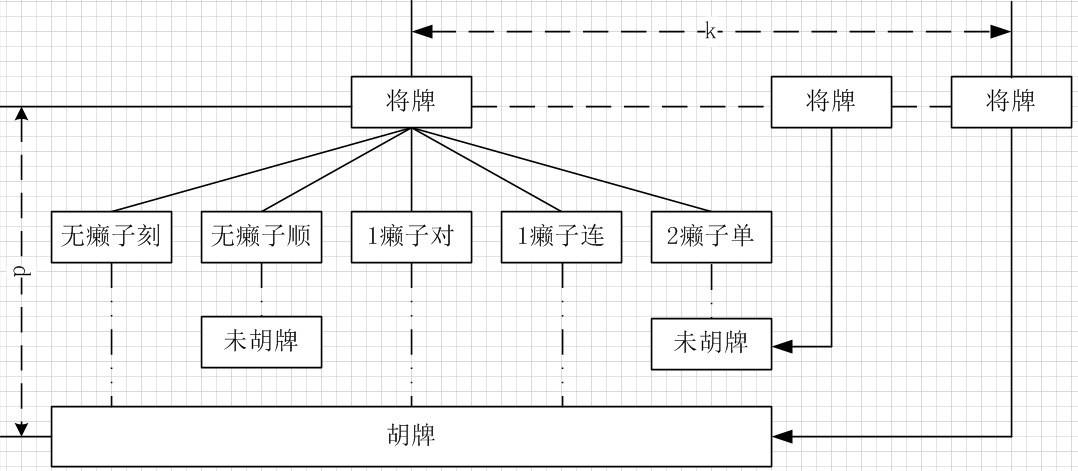
若将牌的可能性为k,树的深度为d,则遍历的时间复杂度为k×5^(d-1),以14张手牌为例,树的深度为5,k取值范围[1,13],取平均为7,则时间复杂度为4375,但通常情况下,那五种情况越靠后,越不太可能胡牌,即分支被截断的可能性越大,其实际时间复杂度会比理论值小得多,但若不考虑靠后的情况,则会忽略一些极端情况下的胡牌,而且一般情况下除去吃碰杠后的牌,实际手牌可能是10张、7张等,少三张就意味着树的深度减1,其时间复杂度会成指数级下降,所以此算法放到服务端也是可行的
通常在麻将结算时都需要获取其分组信息,实际上分组信息就是所有满足深度为d的分支,小于d的都是未胡牌分支,由于树状结构的分支的各节点间存在排列不同但组合相同的情况,所以在最终处理分组结果时,注意对相同组合不同排列的分支除重
听牌即满足来1张牌即可胡牌,所以听牌算法本质就是胡牌算法,由于麻将牌种类有34张,依次带入会很影响性能,所以采用带入一张牌,若带入一张特殊牌,特殊牌的id和所有普通牌的id间隔均大于2,若胡牌,则听任意牌,若带入一张癞子牌后胡牌,则听有限牌
在获取听有限牌时,需分析满足胡牌的分组信息,分组信息实际是上文的树状结构转化后含所有分支的二维数组,数组中的元素实际是树状节点,而听牌信息都保存在含癞子的节点,分为1癞子将、1癞子对、1癞子连、2癞子单四种情况
1癞子将:听节点第一张牌,例如节点[1万癞],则听1万
1癞子对:听节点第一张牌,例如节点[1条1条癞],则听1条
1癞子连:若节点前两张间隔为1,则听两边,例如节点[5万6万癞],则听4万、7万;若间隔为2,则听中间,例如节点[5条7条癞],则听6条
2癞子单:听节点第一张牌及其前后各两张牌,例如节点[5万癞癞],则听3万、4万、5万、6万、7万
在遍历完所有节点并取出其听牌后,由于各节点的听牌可能存在交集,所以需要对听牌结果进行除重
若来一张牌即可胡牌,定义为听牌,来一张牌打出一张牌即可听牌,定义为1向听牌,来一张牌打出一张牌即可1向听牌,定义为2向听牌,则N向听牌可递归定义为来一张牌打出一张牌即可N-1向听牌,而上文中的听牌算法实际是N=0时的N向听牌算法,因此听牌算法也是N向听牌算法的基础
若手牌数为M,按上文定义并依次递推,则N向听牌可理解为从M张手牌中选出N张牌打出,并来N张牌,若听牌,则为N向听牌,其中选出N张牌打出并来N张牌,可转化为把选出的N张牌替换为癞子牌,因此N向听牌的时间复杂度为组合数C{M,N}*Ot,Ot为检查听牌的时间复杂度
由于N是定值,而Ot又依赖听牌算法,所以仅能通过减小M来优化此算法。由于在选出的N张牌中,不太可能出现两张一样的牌,因此可把M张牌进行除重以此来减小M值,但存在一种可能,当手牌中对子数大于等于5时,需要选出一对牌,否则会影响向听结果,也可以提前去除手牌中独立的刻、顺(前后都没有相关牌)来减少M值,当然还有一些尚待研究的方法来减少M值
在选牌算法上,有两种遍历方式,一种是递归深度优先遍历(RDT),一种是循环广度优先遍历(CBT),如下图所示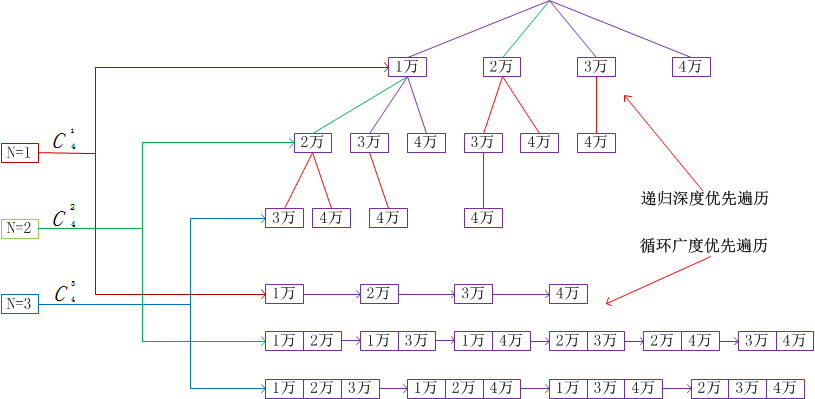
图中是从1万2万3万4万中选择1张、2张、3张的情形,在判断是否为三上一听的时,除了要选择3张之外,还需要选择1张、2张的原因是有可能一副牌为一上一听或两上一听,所以在遍历时,一旦出现选2张、1张就能听牌的情形,就无需考虑3张、2张的情形,如图所示,CBT满足此特性,而RDT不满足此特性,但是可通过剪枝来尽量满足此特性,图中绿色分支表示选2张和1张牌就能听牌,红色分支为被剪部分,很明显如果能把第一层节点中的2万和1万对换,剪枝效率会大大提高,因此可通过对每层节点预排序来提高剪枝效率,而排序的标准就是出牌的优先级,但出牌的算法又依赖向听算法,只能采用按权重出牌来对节点排序,权重算法属于出牌算法的一种,放到下文分析
从上文分析可知,在算法效率上,RDT在剪枝效率达到极限情况下,才能和CBT一样,为何还要介绍RDT呢,原因在于上文提到的拆对子情况,当需要选出一对牌时,CBT难以实现,而RDT可在倒数第三层的节点上针对拆一对牌进行特殊处理,况且经过预排序加剪枝后的RDT和CBT的效率相差并不大,所以在追求准确、牺牲一点效率的情况下可采用RDT,在追求效率、牺牲极端错误结果的情况下可采用CBT
对于业余的机器人可采用按权重出牌,有三个权重因子,牌数量、关联度、位置,牌数量即单、对、刻、杠,按杠>刻>对>单的优先级来出牌,关联度即与前后两张牌的距离,例如3万4万和3条5条,会优先打3条,位置即牌与5的距离,越靠近中间位置越好,5最好,1、9最差,因此三个权重因子的优先级为牌数量>=关联度>>位置,当遇到对和连时,此时牌数量和关联度优先级相等,例如4万4万和5条6条,打四万也行打6条也行,由于位置因子一般情况下可忽略,只有在前两个因子相等时,才会考虑位置因子,所以前两个因子都远大于位置因子。把每张牌按三个权重因子计算一个综合系数后按从小到大排序后,打出第一张牌即可,因此权重只是出牌的简单策略,对于一些复杂结构的牌型,权重策略难以实现最优解,因此上文的RDT采用此算法进行预排序只能提高剪枝效率,不能保证最高剪枝效率
对于专业的机器人可采用按向听出牌,首先按权重依次尝试打牌,然后看打牌后的向听数及听牌数量,向听数越少、听牌数量越多,越优先出牌,按权重依次尝试的目的是尽可能先出差牌,得到较低的向听数,然后取当前最低的向听数来作为向听算法的输入向听数,可大大提高效率。初始输入向听数,可根据当前手牌数和癞子数来确定,理论上可取手牌数/3-癞子数
业余级机器人可按照简单的杠>碰>吃的优先级来处理,但对于专业的机器人,需要区分在叫牌前后向听数的变化来决定是否叫牌
首先获取叫牌前手牌的向听数,对于有摸牌情况,即暗杠和补杠,需要把摸牌加到手牌中,然后用向听算法打出一张牌,再判断此时手牌的向听数,假设为N0,接着获取叫牌后手牌的向听数,因为可能同时存在多种叫牌,所以需要依次尝试
暗杠,即把暗杠相应的四张牌从手牌中移除,判断此时的向听数,假设为N1
补杠,即把摸牌移除,判断此时的向听数,假设为N2
明杠,即把明杠相应的三张牌从手牌中移除,判断此时的向听数,假设为N3
碰吃,即把要参与碰吃的两张牌从手牌中移除,然后用向听算法打出一张牌,若出现碰吃的牌和打牌相等,可忽略此碰吃,接着再判断此时的向听数,假设为N4
若N4>N0,可选择碰吃,否则忽略;对于N1、N2、N3,因为不可能大于N0,且杠牌后还可以摸牌,所以只要不小于N0,即可杠牌
由于在叫牌时,手牌中可能有很多单张,此时的向听数会很大,算法非常耗时,可先获取手牌中所有的无关联单张,然后移除3的整数倍的单张,保留3的余数的单张,由于可能存在1张或2张单张,所以尝试的最大向听数Nm为手牌数/3,一般情况下实际向听数Nr<=Nm,若出现Nr>Nm,出于性能考虑,只能忽略极少数情况,暂时没想到对于存在多个单张的情况下,判断主牌的向听数的完美解决方案,还有待研究
以上思想的源码实现可参考https://github.com/song2010040402102/mahjong
运行源码目录下的script/test.sh,获取测试结果如下:
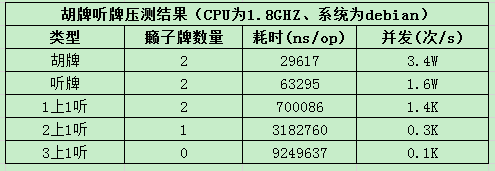
以上算法在不影响服务端运行效率的前提下,可以根据不同水平玩家匹配相应的机器人,且可适配几乎所有地方性麻将,但是算法针对的仅是自己的手牌,属于完备信息博弈,而真实玩家在打麻将过程中,会根据其它玩家打牌和叫牌等行为来分析其它玩家可能的手牌并给出相应的策略,所以麻将属于非完备信息博弈,最好能通过深度学习来解决,有待于研究......